
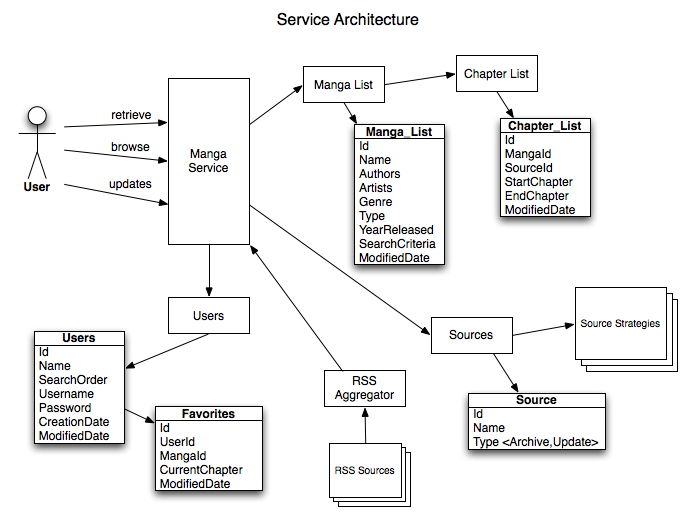

I have documented 3 basic functions: retrieve, browse, updates
In all cases, we assume the user is logged in, so we have access to his/her data
Retrieve – a user requests for a specific manga name/chapter
1. user sends a request for a specific manga name/chapter
2. service goes to the User table and finds the search order
3. based on the search order, checks the Chapter table to see if the manga chapter is available – return first source with chapter
a. if found, based on the Source, use the source strategies to determine correct urls
b. if not found, return not found
Browse – a user wants to see all available mangas
1. user sends request for mangas
2. service sends back current manga list
3. user selects a manga
4. service goes to User table and gets searchOrder, then goes and aggregates Chapter table
a. if not found, service makes a request through ALL source strategies to populate Chapter table
b. if found, return the aggregate chapters available
Updates – a user wants to know if there are any updates to his favorites
1. user sends a request for updates for all manga
2. service goes to User’s Favorites table
3. for every favorites, checks Chapter table for new Chapters
a. if found, return updates
b. if not found, return no updates
RSS Aggregator
1. Listens for updates on the rss feeds of the sources
a. if updates available – update the Chapter table
Source Strategies
These basically are java classes for determining image urls, for getting chapter lists, for analyzing rss feeds.