Here is my first try at creating a logo with css3 and html markup only. No images were used. That is the power of css3.
My Version
![]()
yeah. I know its missing the rounding. I’ll get to that later.
Original Version

Html Markup

Here is my first try at creating a logo with css3 and html markup only. No images were used. That is the power of css3.
My Version
![]()
yeah. I know its missing the rounding. I’ll get to that later.
Original Version
Html Markup
CSS Markup
body
{
background: #fff;
}
#arrow .canvas
{
background: #00539B;
width: 490px;
height: 100px;
margin: 100px 0 0 90px;
}
#arrow .RtRtAngleTriangle
{
width:0;
height: 0;
line-height: 0;
border-top: 100px solid #fff;
border-right: 15px solid #00539B;
position: absolute;
}
#arrow .LtRtAngleTriangle
{
width:0;
height: 0;
line-height: 0;
border-top: 80px solid #fff;
border-left: 15px solid #00539B;
position: absolute;
}
#arrow .LtRt45AngleTriangle
{
width:0;
height: 0;
line-height: 0;
border-top: 40px solid #fff;
border-left: 30px solid #00539B;
position: absolute;
}
#arrow .LtRt45AngleTriangle2
{
width:0;
height: 0;
line-height: 0;
border-top: 26px solid #fff;
border-left: 20px solid #00539B;
position: absolute;
}
#arrow .IsoTrapezoid
{
width:10px;
height: 0;
line-height: 0;
border-bottom: 80px solid #fff;
border-right: 15px solid #00539B;
border-left: 15px solid #00539B;
position: absolute;
}
#arrow .Rectangle
{
background: #fff;
clip:rect(0 75px 201px 0);
position: absolute;
width: 10px;
height: 100px;
}
#arrow .t1
{
left:98px;
top:100px;
}
#arrow .t2
{
left: 120px;
top:120px;
}
#arrow .t3
{
left: 165px;
top: 100px;
}
#arrow .r1
{
left: 180px;
top: 100px;
width: 5px;
height: 80px;
}
#arrow .r2
{
left: 210px;
top: 120px;
width: 15px;
height: 80px;
}
#arrow .t4
{
left: 225px;
top: 160px;
-moz-transform: rotate(180deg);
-webkit-transform: rotate(180deg);
transform: rotate(180deg);
}
#arrow .r3
{
left: 250px;
top: 100px;
width: 20px;
height: 53px;
}
#arrow .t5
{
left: 250px;
top: 153px;
}
#arrow .r2a
{
left: 300px;
top: 120px;
width: 15px;
height: 80px;
}
#arrow .t4a
{
left: 315px;
top: 160px;
-moz-transform: rotate(180deg);
-webkit-transform: rotate(180deg);
transform: rotate(180deg);
}
#arrow .r3a
{
left: 340px;
top: 100px;
width: 20px;
height: 53px;
}
#arrow .t5a
{
left: 340px;
top: 153px;
}
#arrow .r4
{
left: 360px;
top: 173px;
height: 5px;
width: 25px;
}
#arrow .r5
{
left: 385px;
top: 120px;
height: 58px;
width: 15px;
}
#arrow .r6
{
left: 390px;
top: 120px;
height: 5px;
width: 35px;
}
#arrow .r7
{
left: 425px;
top: 120px;
height: 80px;
width: 5px;
}
#arrow .t6
{
left: 425px;
top: 120px;
-moz-transform: rotate(180deg) scalex(0.6);
-webkit-transform: rotate(180deg) scalex(0.6);
transform: rotate(180deg) scalex(0.6);
}
#arrow .t7
{
left: 445px;
top: 100px;
-moz-transform: rotate(180deg) scalex(0.6);
-webkit-transform: rotate(180deg) scalex(0.6);
transform: rotate(180deg) scalex(0.6);
}
#arrow .t8
{
left: 485px;
top: 120px;
-moz-transform: scalex(0.6);
-webkit-transform: scalex(0.6);
transform: scalex(0.6);
}
#arrow .t9
{
left: 525px;
top: 100px;
-moz-transform: rotate(180deg) scalex(0.6);
-webkit-transform: rotate(180deg) scalex(0.6);
transform: rotate(180deg) scalex(0.6);
}
#arrow .t10
{
left:573px;
top:100px;
-moz-transform: rotate(180deg);
-webkit-transform: rotate(180deg);
transform: rotate(180deg);
}
Inspiration from:
http://www.ecsspert.com/twitter.php
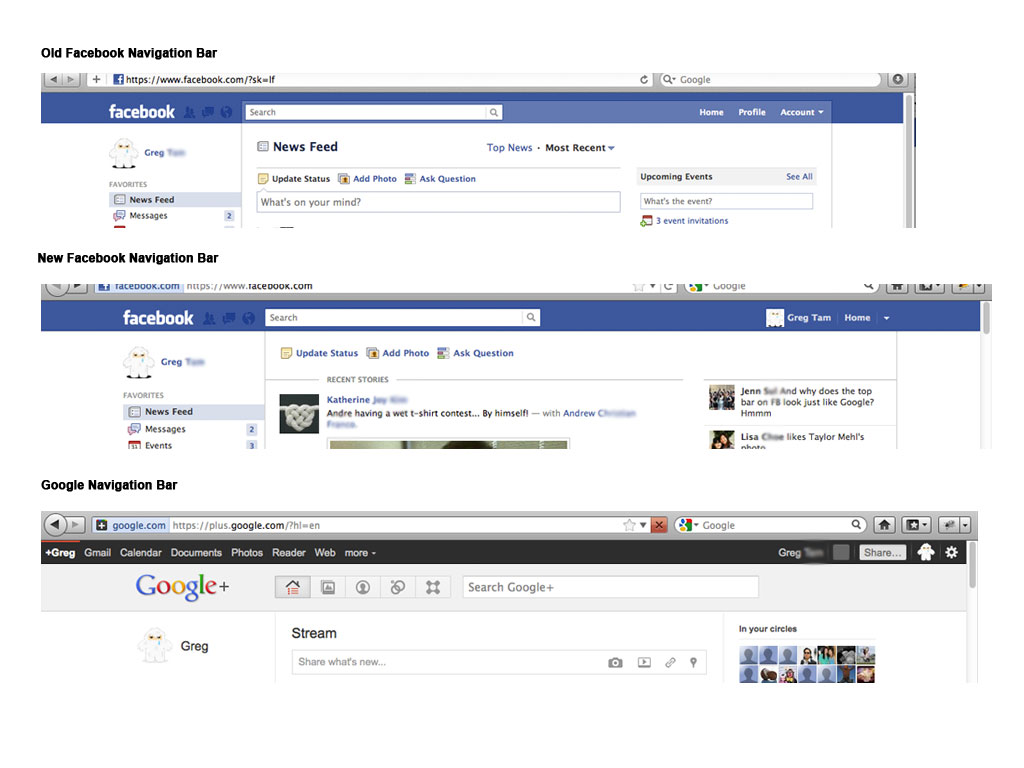
Today, Facebook released a system-wide upgrade that added a new Facebook on top of the current Facebook. This basically allowed real-time streaming of interactions of all social network.

They even moved toward a more unified top navigation bar, which oddly enough look slightly like Google’s new bar. We’re definitely seeing a one up-manship between these 2 companies.
Thinking about it further, what are the reasons for why Facebook would make this change? My guess is that Facebook wants to become a one-stop shop. What do I mean by this? Well essentially Facebook currently brings in revenue through ads, why is Facebook valued so highly by investors? its because in their databases they hold tons of data on a person, this is one step above Google, who controls web search, but the possibilities are limitless when you know what kinds of foods people like, what kind of bands, what kind of interests, sports, etc, AS well as all of this person’s friends and what they like. This is a advertising/marketing goldmine that will give much more directed/successful results.
If we look at history and just a non-scientific observation of my own browsing habits. I’m sure a lot of you also do the same thing, Gmail/GChat has become such a in-grained part of our life, that when we’re on a computer these things are loaded up, they are running constantly. The cool thing about these systems are that you never have to leave the browser. you are never clicking away from gmail. a new mail comes. boom. your mail list shows a new mail. Things happen real-time, it keeps me in one place, it retains my interest and I invest into it.
If you haven’t noticed, Google has already started to mine your email conversations, when you give a date, it’ll automatically show up a calendar event and ask if you want to create it, or if you say Coke, it might automatically show an ad for some other beverage on the side bar.
This is where Facebook is going. They want to capture your attention, keep you on one page, and capture all your interactions you will ever do with your friends and eventually use that data to sell you to the marketers. The new bar, some of the features include a “convenient” way of writing on your friends’ walls for their birthdays. I used to have to right-click to open these people into another tab, but now I’m more inclined to stay on this Facebook page, because I don’t have to navigate away from it. Other features include, mousing over a comment and being able to directly comment into the div that shows up. All these features are designed to keep the user on the same page, make things more convenient, and attempt to lock you into Facebook so that eventually you will not be able to live without it.
Those wall interactions between you and your friends? all captured in Facebooks databases. How often you communicate with someone else? those can be tracked based on how often you write on their wall, or send messages. Facebook can literally and probably already building a scary profile of exactly who you are.
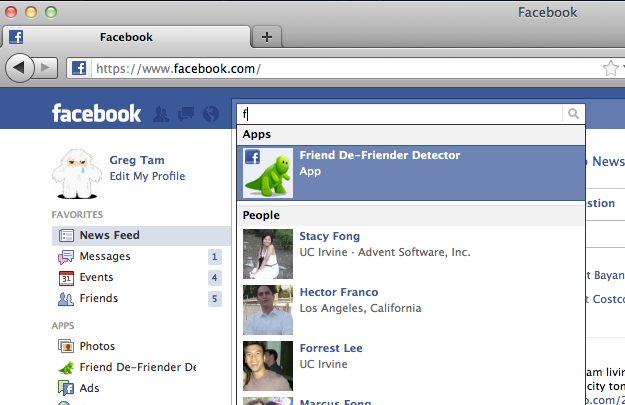

A friend of mine informed me of this article. In the article there is a link that you put in your toolbar to basically figure out what Facebook thinks you are stalking. Now I think thats an interesting concept. So I had to dig a bit further and find out what exactly that metric is.
So the interesting part is that Facebook tracks whenever you type into the Search bar. That generates some ajax calls to things you have searched for most recently. That is what the article talks about.
The first time you load the page, the Search bar fires off this call.
https://www.facebook.com/ajax/typeahead/search/first_degree.php?__a=1&filter[0]=user&lazy=1&viewer=6001041&token=v7&stale_ok=1&__user=600104
obviously my id is 6001041 – so if you want to make the same call, then you can either use the link above or replace my id with yours.
What is this call? its basically gives you an list of things that you have searched for with a negative index sorted to the top, being what you are most likely to search for. In the payload of this json call, they’ve also put the url of the profile picture, thats why it shows up so fast – so once you’ve entered something into the Search Bar, it does a quick search through this index and then displays x number of results while then making ajax calls for the profile pics.
then after you are done finding what you want they fire off this call.
https://www.facebook.com/ajax/typeahead/record_metrics.php?__a=1
this is a post call that stores all sorts of statistical information, pretty interesting to say the least.
As I prepare to do some hardcore coding, I have to learn by example and go through some tutorials to familiarize myself with Xcode, it seems that Apple has put together some pretty decent tutorials.
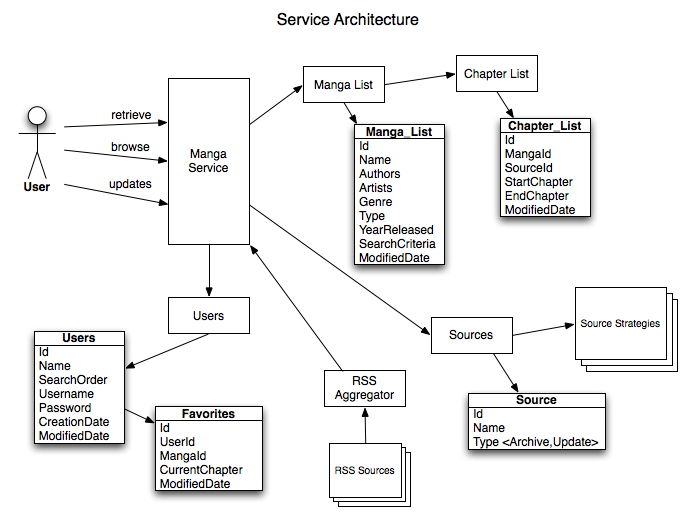

I have documented 3 basic functions: retrieve, browse, updates
In all cases, we assume the user is logged in, so we have access to his/her data
Retrieve – a user requests for a specific manga name/chapter
1. user sends a request for a specific manga name/chapter
2. service goes to the User table and finds the search order
3. based on the search order, checks the Chapter table to see if the manga chapter is available – return first source with chapter
a. if found, based on the Source, use the source strategies to determine correct urls
b. if not found, return not found
Browse – a user wants to see all available mangas
1. user sends request for mangas
2. service sends back current manga list
3. user selects a manga
4. service goes to User table and gets searchOrder, then goes and aggregates Chapter table
a. if not found, service makes a request through ALL source strategies to populate Chapter table
b. if found, return the aggregate chapters available
Updates – a user wants to know if there are any updates to his favorites
1. user sends a request for updates for all manga
2. service goes to User’s Favorites table
3. for every favorites, checks Chapter table for new Chapters
a. if found, return updates
b. if not found, return no updates
RSS Aggregator
1. Listens for updates on the rss feeds of the sources
a. if updates available – update the Chapter table
Source Strategies
These basically are java classes for determining image urls, for getting chapter lists, for analyzing rss feeds.

I was originally going to wireframe the application in OmniGraffle, but I found the stencils to be inadequate, then I looked into Apple’s Interface Builder, but it seemed to not have support for iPad. so now I’m downloading the latest one. Till tomorrow.
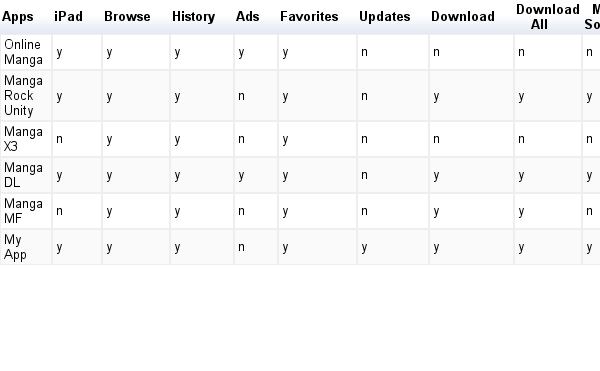
So in order to decide what features or the the reason why I’m building this product, it has to not exist or do something better. If you look at Google, they were a better search engine then the current existing search engines. In the same vein, I want to build a better Manga Management reader.
What do the other apps have? and what will mine have? see the table below.

The key here is updates – my app will be able to let the user know when updates are available for the favorites that they have selected. Some of the apps do have updates, but they seem counter intuitive and don’t work properly.





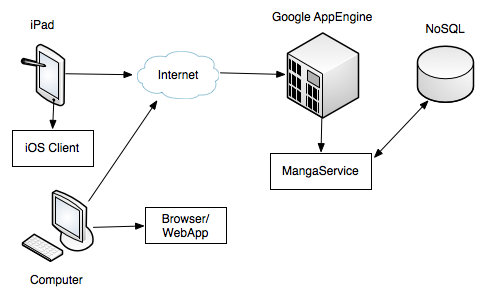
I’m going to start a new series. I’m going to try to take a couple hours out of everyday to work on this new side project. I’m going to build an iOS application specifically for the iPad. This project will serve 3 purposes;
1. meet a need where the current manga applications on iPad don’t meet
2. to familiarize myself with iOS development
3. to keep my programming and technology fresh.
Purpose: Design and implement a iOS application that will allow a user to receive updates, download, and read Manga titles in a nice looking UI.
Target Audience: iPad only
Technology: Google App Engine (for backend), XCode (iOS development)
Now I’m kind of debating whether I should go with Sencha’s Touch framework, perhaps when I’m prototyping, I’ll use it to see some results.

I’ve already got a basic architecture down. I’ll be creating a REST service on Google App Engine, which will do most of the heavy lifting. The iOS application will make calls to this service to receive updates about the manga the user is currently reading, if there are updates, and also how to grab the images for each chapter.

Founded in 1986, Hamann Motorsport has been a consistent leader in aftermarket auto design and tuning.

Technology: PHP, JQuery, HTML, CSS
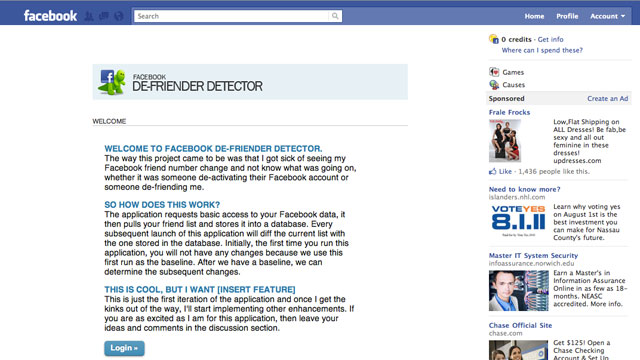
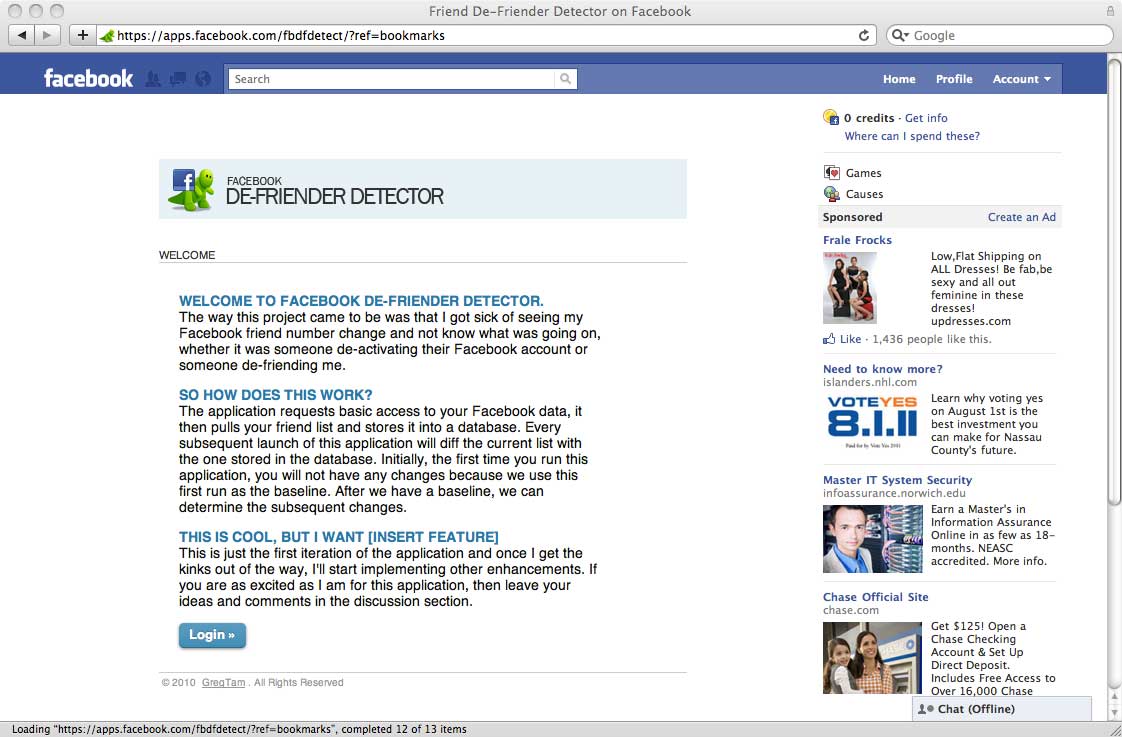
The way this project came to be was that I got sick of seeing my Facebook friend number change and not know what was going on, whether it was someone de-activating their Facebook account or someone de-friending me.
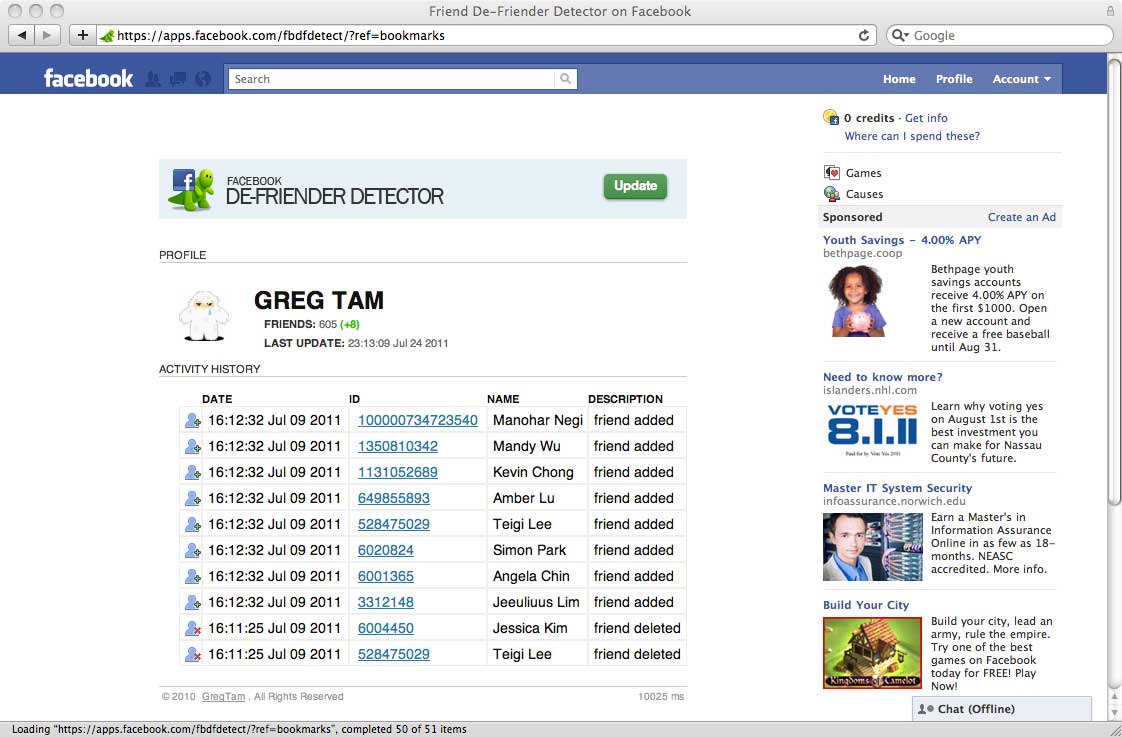
Technology: Google App Engine, Java, JQuery, CSS, HTML