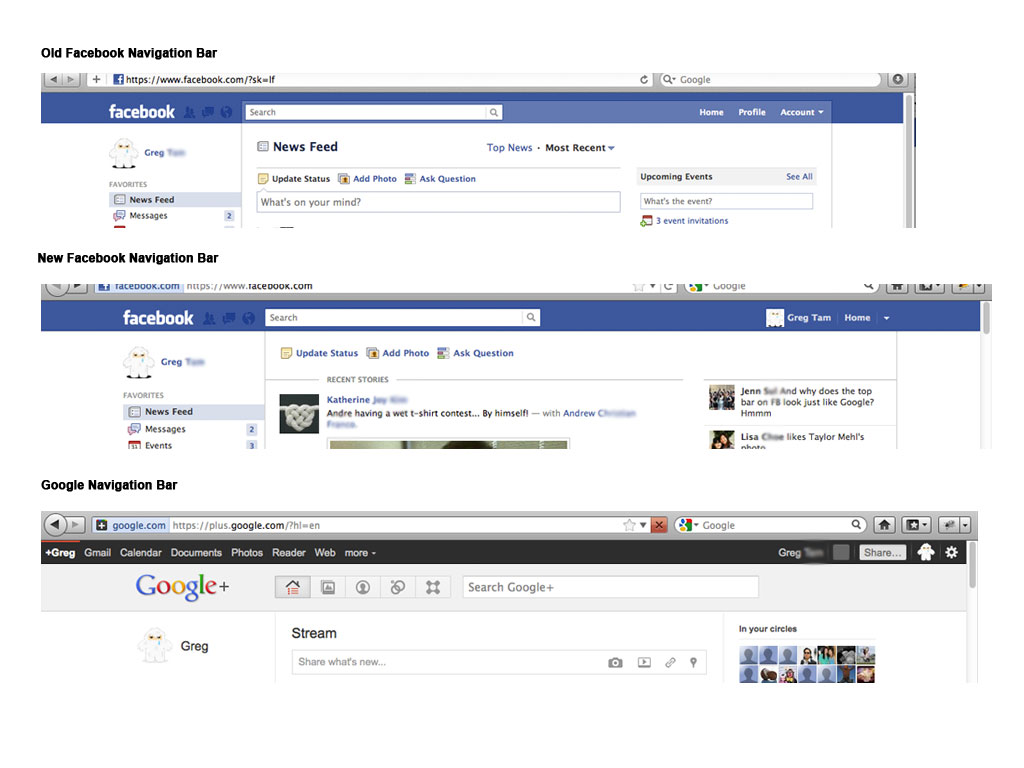
Today, Facebook released a system-wide upgrade that added a new Facebook on top of the current Facebook. This basically allowed real-time streaming of interactions of all social network.

They even moved toward a more unified top navigation bar, which oddly enough look slightly like Google’s new bar. We’re definitely seeing a one up-manship between these 2 companies.
Thinking about it further, what are the reasons for why Facebook would make this change? My guess is that Facebook wants to become a one-stop shop. What do I mean by this? Well essentially Facebook currently brings in revenue through ads, why is Facebook valued so highly by investors? its because in their databases they hold tons of data on a person, this is one step above Google, who controls web search, but the possibilities are limitless when you know what kinds of foods people like, what kind of bands, what kind of interests, sports, etc, AS well as all of this person’s friends and what they like. This is a advertising/marketing goldmine that will give much more directed/successful results.
If we look at history and just a non-scientific observation of my own browsing habits. I’m sure a lot of you also do the same thing, Gmail/GChat has become such a in-grained part of our life, that when we’re on a computer these things are loaded up, they are running constantly. The cool thing about these systems are that you never have to leave the browser. you are never clicking away from gmail. a new mail comes. boom. your mail list shows a new mail. Things happen real-time, it keeps me in one place, it retains my interest and I invest into it.
If you haven’t noticed, Google has already started to mine your email conversations, when you give a date, it’ll automatically show up a calendar event and ask if you want to create it, or if you say Coke, it might automatically show an ad for some other beverage on the side bar.
This is where Facebook is going. They want to capture your attention, keep you on one page, and capture all your interactions you will ever do with your friends and eventually use that data to sell you to the marketers. The new bar, some of the features include a “convenient” way of writing on your friends’ walls for their birthdays. I used to have to right-click to open these people into another tab, but now I’m more inclined to stay on this Facebook page, because I don’t have to navigate away from it. Other features include, mousing over a comment and being able to directly comment into the div that shows up. All these features are designed to keep the user on the same page, make things more convenient, and attempt to lock you into Facebook so that eventually you will not be able to live without it.
Those wall interactions between you and your friends? all captured in Facebooks databases. How often you communicate with someone else? those can be tracked based on how often you write on their wall, or send messages. Facebook can literally and probably already building a scary profile of exactly who you are.